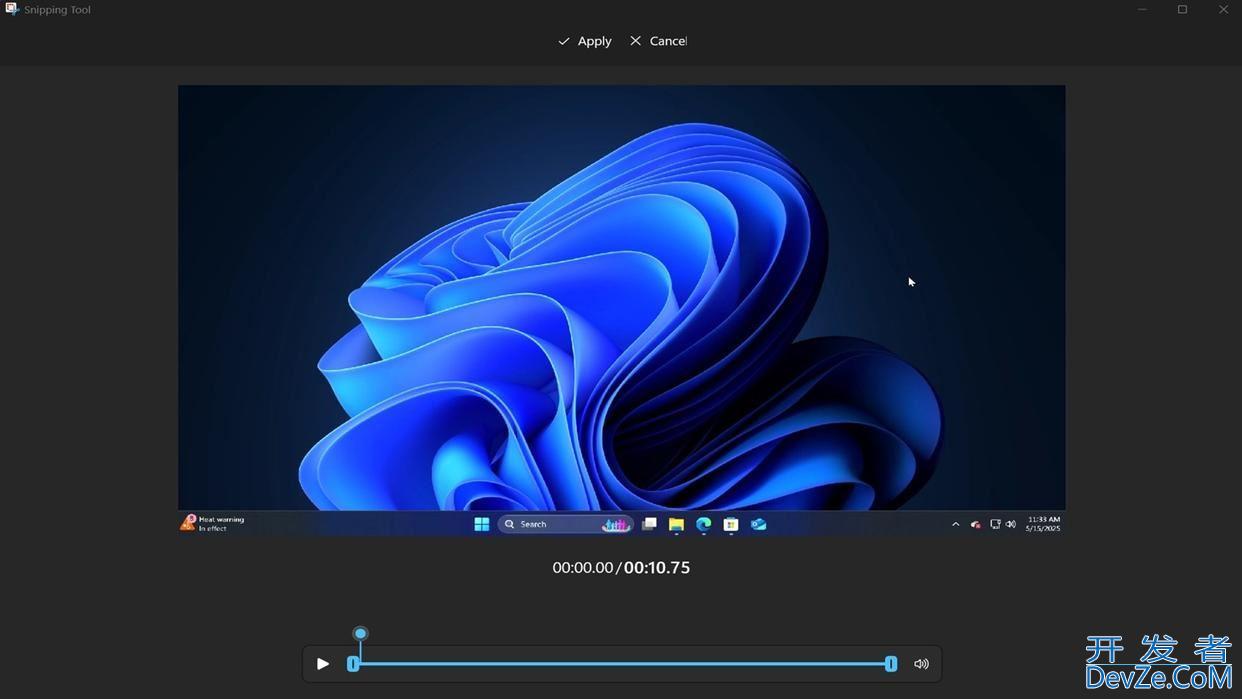
科技媒体 Windows Latest 5 月 16 日发布博文,报道称微软升级 Windopythonws 11 系统内置的截图工具(Snipping Tool),全面编程客栈推送剪辑工具(Trim tool)功能,可简单剪辑录频内容。
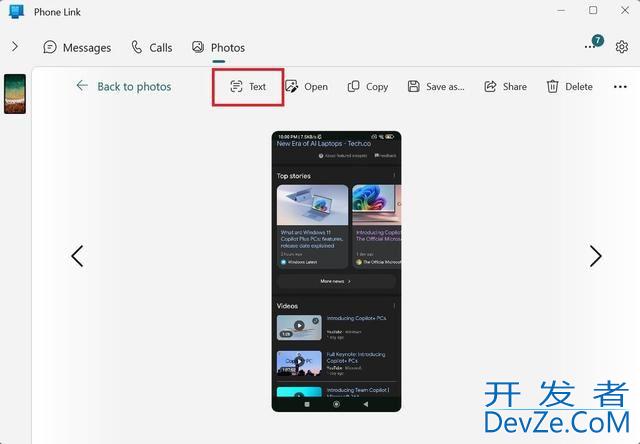
微软公司今天面向所有 Windows 10、Windohttp://www.devze.comws 11 编程用户,开放推出了 OCR 提取安卓手机照片文本功能。
目录安装Tesseract OCR安装php扩展导入必要的模块读取图片对图片进行预处理使用Tesseract进行OCR识别总结tesseract-ocr是一个流行的开源OCR引擎库,它使用C++编写。 PHP作为一种流行的服务器端语言,也提供了一些ocr
目录介绍Tesseract OCR整体流程步骤详解1. 加载图像2. 预处理图像3. 调用OCR引擎4. 获取识别结果5. 输出识别结果总结介绍
I am trying to implement Epshtein\'s paper(Detecting text in natural scenes with stroke width transform(2010)) on text detection in natural images.
I am developing a sample scan activity for card reading(OCR) using Tesseract tools. It works fine on emulator (using android 2.2) and scans given card from sdcard fastly and easily.
I have over 30,000 pdf files. Some files are already OCR and some are not. Is there a way to find out which files are already OCR\'d and which pdfs are image only?
Therequirement is to get information on the different types of cards such asCredit ,Debit, License, SSN, medical insurances etc.
Using the javaocr framework from sourceforge. Trying to scan letters from a image, and training the system to recognize them.
I try to upload image to google docs using code I setup access_token and access_token_secret $uri = \'https://docs.google.com/feeds/documents/private/full?ocr=true\';
 加载中,请稍侯......
加载中,请稍侯......