目录引言为什么需要编辑PDF文档?安装PDF文档编辑库修改PDF中的文本修改现有文本添加新文本向PDF添加图片修改PDF元数据向PDF添加或删除页面添加页面删除页面向PDF添加水印其他PDF编辑功能总结引言
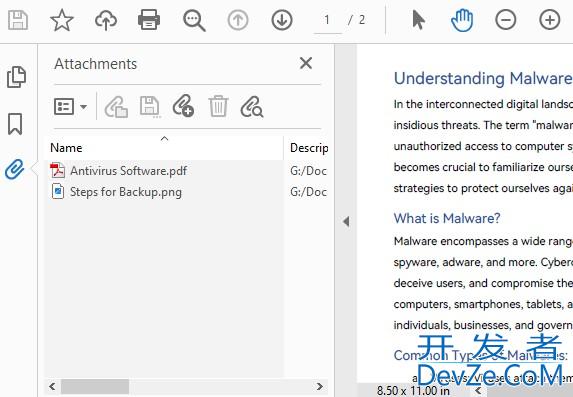
目录1. 初始化 PDF 文档2. 添加外部文件作为 PDF 附件3. 在 PDF 页面添加附件注释4. 总结在文档管理和报表生成中,将相关文件直接嵌入 PDF 可以大大提高信息整合度,让收件人无需额外查找即可访问所有资源。python 结
目录PDF转html的挑战与机遇使用Spire.PDF for python实现PDF到HTML的转换库的安装指南核心转换代码示例高级转换选项(提及)转换后的HTML优化与注意事项总结与展望PDF(Portable Document Format)作为一种广泛使用的
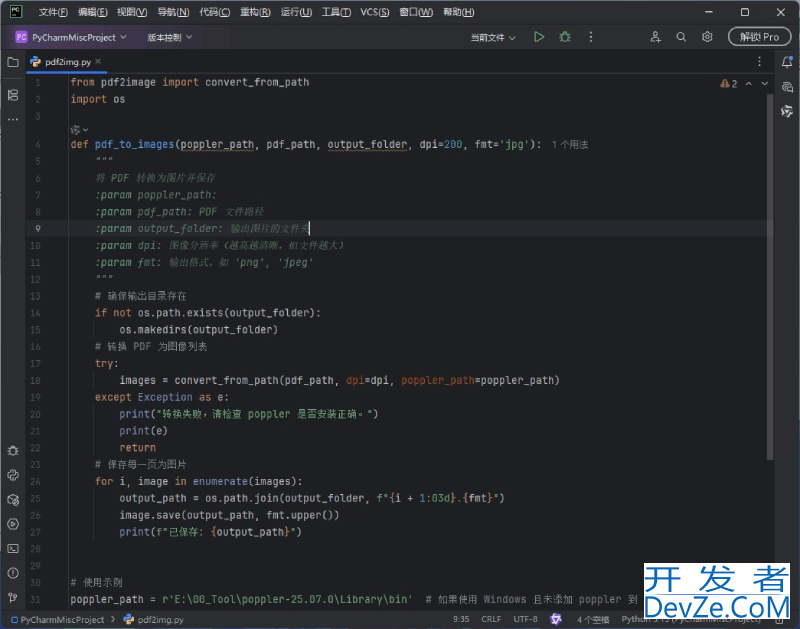
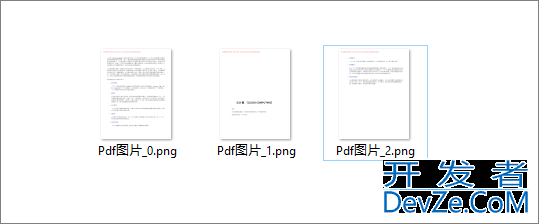
目录第一步:安装依赖库第二步:安装 poppler第三步:python 代码示例方法补充在 Python 中将 PDF 文件保存为图片,最常用的方法是使用 pdf2image 库。这个库实际上是 poppler 工具的 Python 封装,能够将 PDF 的每一

目录1. 引言2. 环境准备和基础库介绍2.1 安装必要的库2.2 各库的主要功能3. Excel自动化处理3.1 基础Excel操作3.2 高级Excel功能4. Word文档自动化4.1 基础Word操作4.2 高级Word功能5. PDF文档自动化5.1 基础PDF操作
目录一、核心原理二、所需工具二、PDF文字识别提取步骤步骤1:导入核心模块步骤2:初始化 OCR 引擎(关键配置)步骤3:加载 PDF 并转换为图像步骤4:OCR识别图像并保存文本四、常见问题&解决方案扫描件 PDF 本质
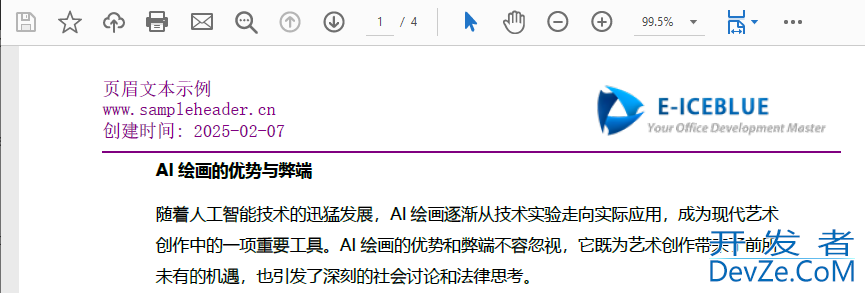
目录python 在 PDF 中插入页眉Python 在 PDF 中添加页脚总结在制作 PDF 文件时,我们常常会遇到一个问题:文件内容虽然齐全,但少了页眉页脚,显得不够专业。尤其是在生成报告、论文或合同等正式文档时,如果页面上都
目录为什么需要裁剪 PDF 页面使用 python 裁剪 PDF 页面1. 安装依赖2. 基本裁剪操作裁剪 PDF 并导出为图片1. 裁剪单页并导出为图片2. 批量裁剪所有页面并导出为图片总结在日常工作中,处理 PDF 文件是非常常见的需求
目录引言为什么选择 python 进行 PDF 到 Excel 的转换?Spire.PDF for Python 简介与安装安装命令使用 Spire.PDF for Python 实现 PDF 到 Excel 的转换完整转换代码总结引言
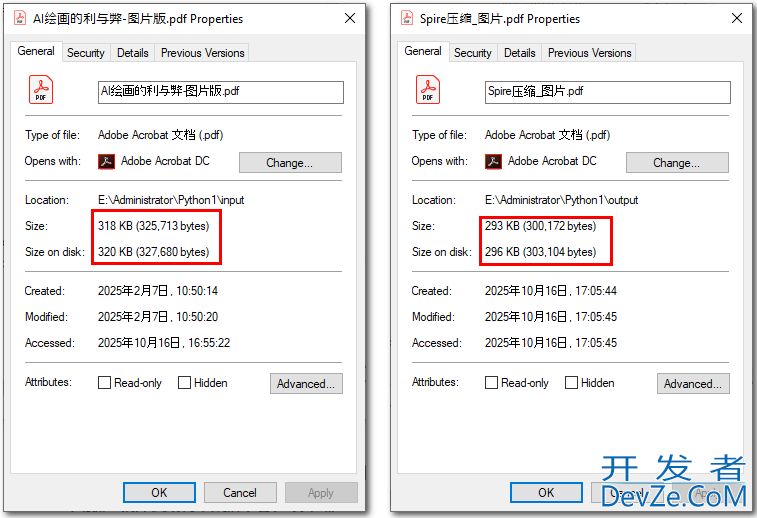
目录Spire.PDF for python:高效压缩 PDF 文件压缩图片:减小 PDF 文件体积的常用方法优化字体:进一步减小文件体积ASPose.PDF:通过优化字体实现 PDF 压缩PyPDF2:快速压缩 PDF 文件总结在日常工作中,压缩 PDF 文件
 加载中,请稍侯......
加载中,请稍侯......