目录引言环境准备加载 CSV 文件导出为 PDF页面布局调整(可选)数据处理与优化建议使用场景总结引言
目录为什么需要删除PDF中的超链接认识spire.pdf for python库使用Python删除PDF超链接的步骤与实践导入库与加载PDF文档定位并移除超链接保存修改后的PDF文档进一步的思考与拓展总结在数字编程客栈文档时代,PDF文件因

目录引言一、工具需求与技术选型1.1 工具核心需求1.2 技术选型二、环境搭建步骤2.1 安装python依赖库2.2 安装wkhtmltopdf工具三、工具代码实现3.1 整体代码框架3.2 代码模块详细解释3.2.1 参数解析模块(parse_args函
目录引言环境准备与库安装使用python拆分PDF使用Python合并PDF总结引言 在日常办公和数据处理中,PDF文档因其稳定性和通用性而广泛应用。然而,我们经常会遇到需要将多个PDF报告合并成一份完整文档,或者将一份冗长的
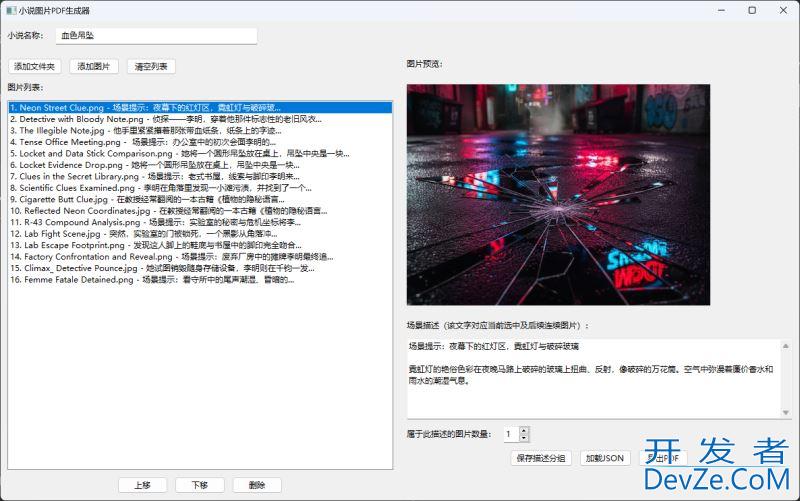
目录项目概述核心功能技术架构依赖库分析核心数据结构ImageItem 类GUI 界面设计布局结构关键UI组件1. 标题输入区2. 图片列表框3. 图片预览区4. 分组控制核心功能实现1. 图片管理批量添加文件夹单张/多张添加2. 图片预
目录引言安装 python PDF 库基本 PDF 转 html 示例自定义 HTML 输出将 PDF 输出到 HTML 流总结引言
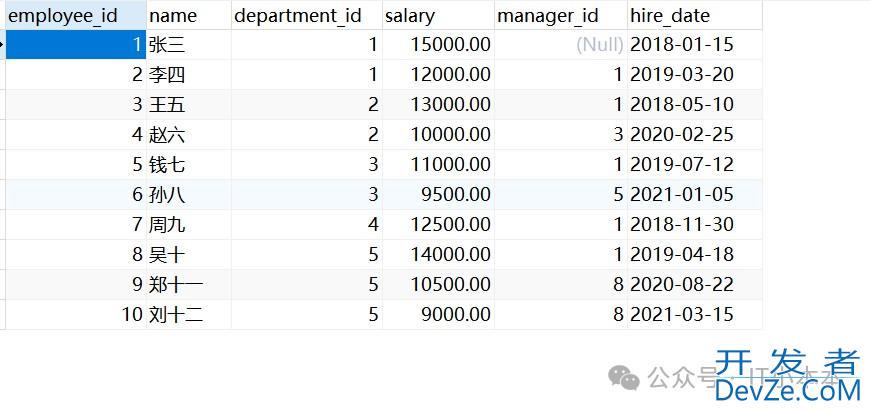
目录技术栈与核心功能主要技术组件功能亮点核心代码解析1. 数据库连接与数据获取2. 数据提取与表结构校验3. 个性化PDF生成运行前准备运行后的效果本文将介绍如何使用python构建一个自动化工具,实现从mysql数据库提取
目录安装 Spire.PDF for python1. 按页码范围拆分 PDF2. 拆分为单页 PDF3. 按固定页数间隔拆分4. 高级拆分场景处理加密 PDF按书签或内容拆分总结在工作和学习中,PDF 文档已经成为我们最常见的文件格式之一。它可以完
目录一、前言二、文本提取方法1. pdfplumber:精准提取文本与表格2. fitz(PyMuPDF):快速提取文本与图像3. PyPDF2:简单文本提取的利器4. pdfminer:深度自定义提取逻辑5. pdfquery:提取特定区域文本6. pytessera
目录引言方案一:使用PyPDF2库(推荐)特性安装方法完整代码示例方案二:使用pdfplumber库特性安装方法完整代码示例方案对比高级技巧最佳实践建议常见问题解答总结编程引言
 加载中,请稍侯......
加载中,请稍侯......