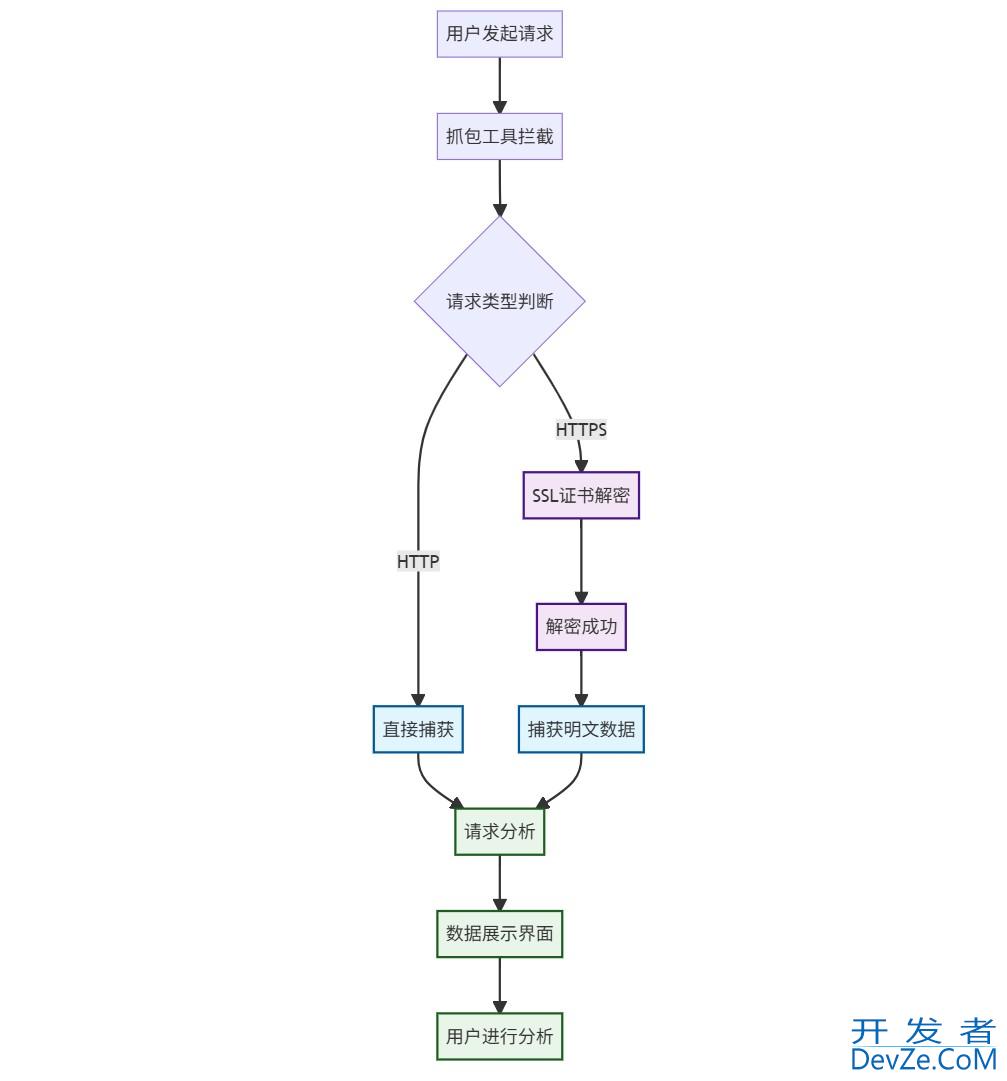
目录抓包工具概述什么是抓包工具主流抓包工具对比抓包工具核心功能解析HTTP/HTTPS请求拦截请求重放与修改Mermaid可视化图表图1:抓包工具工作流程图图2:爬虫抓包分析时序图图3:抓包数据分析架构图图4:反爬机制识别
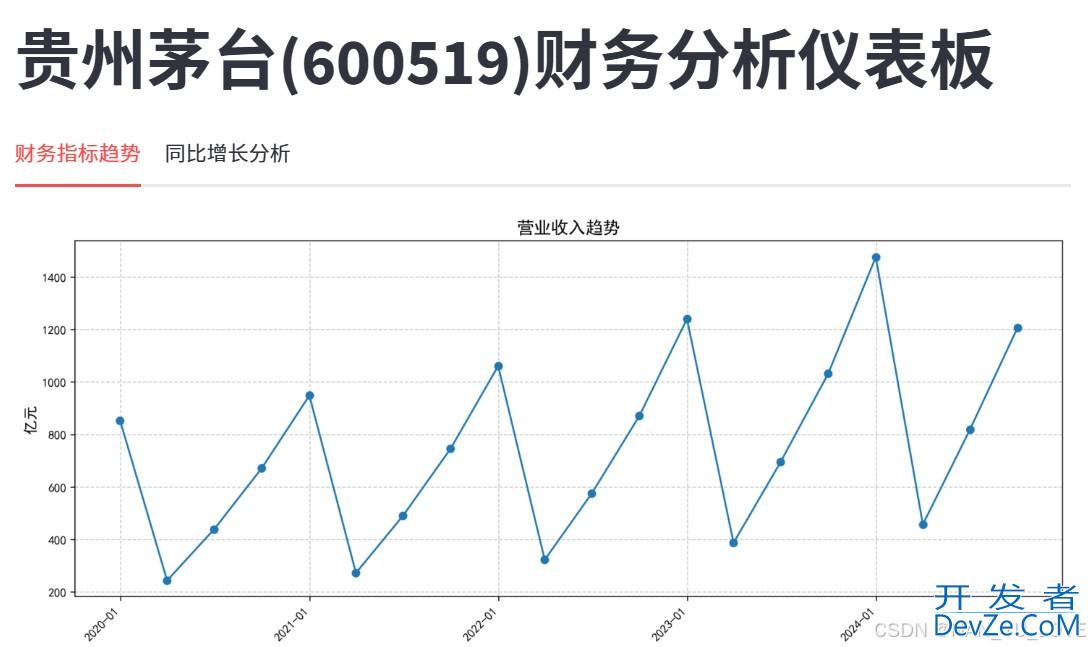
目录一、前言二、核心知识点梳理1、Akshare数据获取2、Pandas数据处理3、Matplotlib可视化4、Streamlit Web应用5、财务分析基础二、代码逐段解析1、导入依赖库2、数据获取与保存3、数据处理与指标计算4、Streamlit可
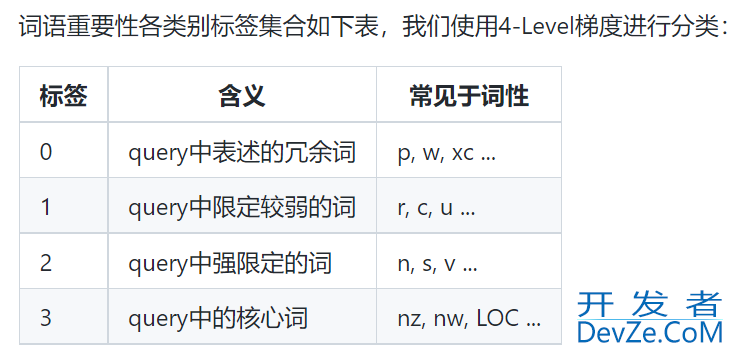
目录1. 基于TF-IDF算法的中文关键词提取:使用jieba包实现2. 基于TextRank算法的中文关键词提取:使用jieba包实现3. 基于TextRank算法的中文关键词提取(使用textrank_zh包实现)3. 没说基于什么算法的中文词语重要性

目录一、为什么选择aiohttp?1.1 传统爬虫的瓶颈1.2 aiohttp的异步优势二、核心组件拆解2.1 信号量控制并发2.2 连接池优化2.3 异常处理机制三、完整实现案例3.1 基础版本四、性能优化实战4.1 代理池集成4.2 动态URL生
目录前言安装zhconv模块使用示例1、通用函数convert2、快捷函数to_traditional和to_simplified注意事项总结在python中,你可以使用zhconv库来进行简体中文和繁体中文之间的转换。zhconv是一个轻量级的Python库
目录介绍newspaper包newspaper包示例教学 单条新闻爬取示例同网站下多条新闻爬取1、先构建新闻源2、文章缓存3、提取源类别4、提取源新闻网站的品牌和描述5、查看新闻链接6、提取单篇文章7、提取新闻源下所有新闻

目录Pyppeteer 自动化测试的三大典型问题1. 下载效率低下2. 网络兼容性问题3. 架构适配难题4.性能对比解决方案1.镜像源替换:接入华为云镜像加速下载,访问华为镜像源2. 常见问题处理结语Pyppeteer 自动化测试的三大
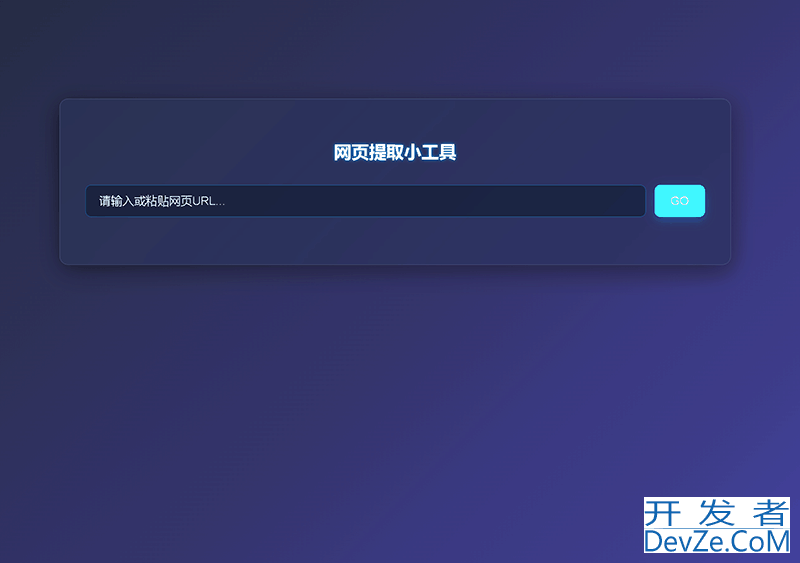
目录不管怎么说,先睹为快工具效果图:工具简单流程图为什么需要专门的html解析库?只用正则表达式不够吗?BeautifulSoup:上手简单的HTML解析1. 安装和准备2. 按标签名访问3. 用 find() 和 find_all() 精确查找 (常
思路——抓取网页数据并生成 Excel 文件的过程可以分为以下几个步骤:
目录项目概述2.1 游戏概念2.2 游戏特色2.3 目标玩家群体技术选择与环境准备3.1 开发环境3.2 依赖库游戏设计4.1 游戏核心机制4.2 游戏背景4.3 角色与资源4.4 随机事件系统4.5 任务与成就系统代码结构与实现5.1 项目结
 加载中,请稍侯......
加载中,请稍侯......