MySQL 增删改查操作与 SQL 执行顺序详解
目录
- 一、CRUD 核心操作
- 1.1 数据约束
- 1tnxCww.2 删除数据
- 1.3 去重
- 1.4 查询条件与过滤
- 二、CRUD 操作示例
- 2.1 创建数据库
- 2.2 创建表
- 2.3 增(Create)
- 2.4 删(Delete)
- 2.5 改(Update)
- 2.6 查(Read)
- 三、SQL 执行顺序
一、CRUD 核心操作
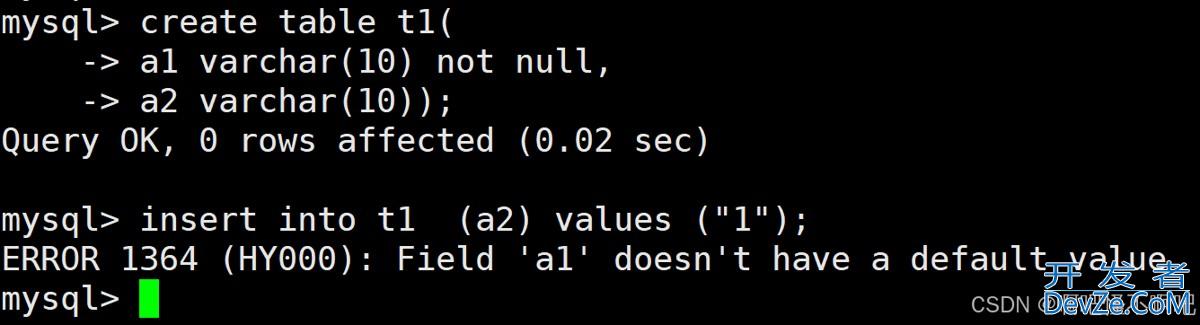
数据库中的 CRUD 指的是对表数据的增(Create)、删(Delete)、改(Update)、查(Select)四类基本操作。为了保证数据完整性和业务约束,表设计中常用 五大约束:NOT NULL、AUTO_INCREMENT、UNIQUE、PRIMARY KEY、FOREIGN KEY,是数据库操作的基础核心。
1.1 数据约束
为保证数据库中数据的完整性与一致性,存在 5 大约束:
not null非空约束:确保字段的值不能为空。例如,在学生表的“姓名”字段设置该约束后,插入学生记录时必须填写姓名。auto_increment自增约束:常用于主键字段,使字段值在插入新记录时自动递增。比如学生表的“学号”字段,每次新增学生,学号会自动加 1。unique唯一约束:保证字段的值在表中是唯一的,避免重复。像课程表的“课程名称”字段,不能有重复的课程名。primary主键约束:同时包含“非空 + 唯一”属性,用于唯一标识表中的每条记录,一个表只能有一个主键。例如学生表的“学号”字段可作为主键,唯一确定每个学生。foreign外键约束:用于建立表与表之间的关联,确保参照完整性。比如学生选课表中的“学生学号”字段可作为外键,关联学生表的“学号”主键,保证选课记录对应的学生存在。
1.2 删除数据
mysql 删除数据的几种方式有什么区别?
在 MySQL 中,删除数据主要有三种方式:
DROP、TRUNCATE和DELETE。DROP属于 DDL 操作,会直接删除整张表,包括表结构、数据、索引等所有对象,执行最快但无法回滚;TRUNCATE也是 DDL,只清空表中所有数据,保留表结构,同时会重置自增主键,速度也很快,同样无法回滚;而DELETE是 DML 操作,逐行删除数据,可以通过WHERE条件选择性删除,并且支持事务回滚,但速度相对较慢。
删除数据有 drop(DDL)、truncate(DDL)、delete(DML)三种方式,区别如下:
① drop (DDL)
- 作用:删除整张表的结构以及表数据(包括表结构 + 表数据 + 索引 + 约束 + 触发器 等所有相关对象)。
- 速度:快(直接移除元数据,释放空间)
- 回滚:通常不能回滚。执行后会释放表所占的磁盘空间。
- 例如:执行
DROP TABLE student;学生表的结构和所有学生数据都会被删除。
② truncate (DDL)
- 作用:只删除表中的数据,表的结构、索引等其他对象保留,且会将自增字段的值初始化为 1
- 速度:较快(以“页”为单位进行删除操作,而不是逐行删除)
- 回滚:通常不能回滚,会释放数据占用的空间
- 比如 :
TRUNCATE TABLE student;后,学生表数据被清空,如果再次插入数据,自增学号从 1 开始。
③ delete (DML)
- 作用:逐行删除符合条件的记录,表的结构、索引等其他对象保留,可以指定
WHERE条件进行部分删除。 - 速度:慢(记录逐行删除,产生 undo/redo、可能触发触发器、影响索引、写入 binlog)
- 回滚:支持回滚(在事务中使用 delete 可通过 rollback 恢复)。
- 例如:
DELETE FROM student WHERE age > 20;只会删除年龄大于 20 的学生记录。
1.3 去重
去重用于获取表中不重复的数据,主要有以下两种方式:
① group by column
通过对指定列进行分组,将相同值的行归为一组,从而实现去重效果。常与聚合函数(COUNT, SUM, AVG 等)配合用于统计或去重。
示例(统计每个班级人数):
SELECT class, COUNT(*) AS cnt FROM student GROUP BY class;
② select distinct column
示例(去重班级):列出学生表中所有不同的班级名称。
SELECT DISTINCT class FROM student;
1.4 查询条件与过滤
条件判断用于在数据库操作中根据特定条件筛选数据或执行操作,常见的有以下几种场景:
① from… where…
- 在 SELECT、UPDATE、DELETE 操作中,通过
WHERE子句设置条件,筛选出符合要求的数据。 - 通常比
having更早执行 - 只能引用行级列或表达式,不能引用聚合结果。
SELECT * FROM student WHERE age > 19; DELETE FROM student WHERE id = 3; UPDATE student SET age = age + 1 WHERE class = '计算机1班';
② group by… having…
- 先通过
GROUP BY对列进行分组,再用HAVING子句对分组后的结果设置条件进行筛选。 - 可以引用聚合函数(例如
HAVING COUNT(*) > 1)。
示例:筛选出平均年龄大于 20 的班级及其平均年龄
SELECT class, AVG(age) FROM student GROUP BY class HAVING AVG(age) > 20;
③ A join B on condition
- 用于多表连接查询,通过
ON指定连接条件,将两个或多个表中相关联的数据组合在一起。 WHERE可继续对连接后的结果集进行过滤。
SELECT s.name, c.name FROM student s JOIN course c ON s.id = c.student_id WHERE s.age > 18;
假设课程表有 student_id 外键关联学生表 id,获取学生姓名和所选课程名称。
二、CRUD 操作示例
2.1 创建数据库
- 创建数据库:
CREATE DATABASE 数据库名 DEFAULT CHARACTER SET utf8;,用于创建新的数据库并设置字符集为utf8,例如CREATE DATABASE school DEFAULT CHARACTER SET utf8;。 - 删除数据库:
DROP DATABASE 数据库名;,会删除指定数据库及其所有对象,如DROP DATABASE school;。 - 选择数据库:
USE 数据库名;,用于指定当前要操作的数据库,如USE school;。
CREATE DATABASE `mydb` DEFAULT CHARACTER SET utf8; USE `mydb`; DROP DATABASE `mydb`;
2.2 创建表
创建表:使用 CREATE TABLE 语句创建表,可指定字段、类型、约束等。
例如创建学生表:
CREATE TABLE IF NOT EXISTS `student` ( `id` INT UNSIGNED AUTO_INCREMENT COMMENT '学号', `name` VARCHAR(40) NOT NULL COMMENT '姓名', `age` TINYINT UNSIGNED COMMENT '年龄', `class` VARCHAR(20) COMMENT '班级', PRIMARY KEY (`id`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='学生表';
创建课程表:
CREATE TABLE IF NOT EXISTS `course` ( `id` INT UNSIGNED AUTO_INCREMEandroidNT COMMENT '课程ID', `name` VARCHAR(40) NOT NULL COMMENT '课程名称', `teacher` VARCHAR(20) NOT NULL COMMENT '教师', `credit` TINYINT UNSIGNED COMMENT '学分', PRIMARY KEY (`id`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='课程表';
- 删除表:
DROP TABLE表名;,会删除表及其所有数据,如DROP TABLE student;。
2.3 增(Create)
插入数据:使用 INSERT INTO 语句向表中插入数据
例如向学生表插入数据:
INSERT INTO `student` (`name`, `age`, `class`) VALUES
('tnxCww张三', 20, '计算机1班'),
('李四', 19, '计算机2班'),
('王五', 21, '软件工程1班');
向课程表插入数据:
INSERT INTO `course` (`name`, `teacher`, `credit`) VALUES
('数据库原理', '张老师', 3),
('操作系统', '李老师', 4),
('计算机网络', '王老师', 3);
2.4 删(Delete)
删除表与清空数据:使用 DELETE FROM 语句删除表中数据,可通过 WHERE 子句设置条件,
例如:
DELETE FROM `student` WHERE id = 3; -- 删除ID为3的学生 DELETE FROM `student` WHERE name = '李四'; -- 删除姓名为李四的学生 DELETE FROM `student` WHERE age > 20; -- 删除年龄大于20的学生
清空数据表:
TRUNCATE TABLE 表名;,如TRUNCATE TABLE student;,清空学生表数据,自增字段置 1。DELETE FROM 表名;,如DELETE FROM student;,逐行清空学生表数据,自增字段从之前的值继续。
示例:
DROP TABLE `student`; -- 删除表结构与数据 TRUNCATE TABLE `student`; -- 清空数据(重置自增) DELETE FROM `student`; -- 逐行删除(可加 WHERE)
2.5 改(Update)
更新数据:使用 UPDATE 语句更新表中数据,通过 SET 子句设置新值,WHERE 子句设置条件
例如:
UPDATE `student` SET `age` = 22 WHERE id = 1; -- 更新年龄 UPDATE `student` SET `class` = '计算机3班' WHERE id = 2; -- 更新班级 UPDATE `student` SET `age` = `age` + 1; -- 所有学生年龄加1
2.6 查(Read)
查询数据:使用 SELECT 语句查询表中数据,可进行简单查询、条件查询、排序查询、统计查询等
例如:
SELECT * FROM `student`; -- 查询所有学生 SELECT `name`, `age` FROM `student`; -- 查询指定列 SELECT * FROM `student` WHERE age > 19; -- 条件查询 SELECT * FROM `student` WHERE class LIKE '计算机%'; -- 模糊查询 SELECT * FROM `student` ORDER BY age DESC; -- 排序查询 SELECT COUNT(*) as total FROM `student`; -- 统计数量
三、SQL 执行顺序
写 SQL 是按如下顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT ...
但实际执行顺序并不是这样!
数据库在执行 SQL 时,是按照逻辑执行步骤从底层一层层向上处理的:| 执行阶段 | 关键字 | 说明 |
|---|---|---|
| ① | FROM | 首先确定要从哪张表获取数据,生成笛卡尔积。 |
| ② | ON | 如果涉及多表连接(JOIN),在这一阶段根据连接条件过滤行。 |
| ③ | JOIN | 执行连接操作,合并结果集。 |
| ④ | WHERE | 过滤不符合条件的记录,只保留满足条件的数据。此阶段不能使用聚合函数。 |
| ⑤ | GROUP BY | 对筛选后的数据进行分组,为聚合计算(如 COUNT、SUM 等)准备。 |
| ⑥ | HAVING | 对分组结果再进行条件过滤,这时可以使用聚合函数。 |
| ⑦ | SELECT | 确定要查询哪些列或表达式,执行投影操作。 |
| ⑧ | DISTINCT | 对结果去重(如果指定了 DISTINCT)。 |
| ⑨ | ORDER BY | 按指定的列或表达式对结果排序。 |
| ⑩ | LIMIT | 返回指定范围的记录,例如分页查询。 |
- 书写顺序是“
SELECT在前”,但实际执行时SELECT在中间阶段(第7步),因此 SELECT 中定义的别名不能在 WHERE 中使用,但可在ORDER BY中使用。 WHERE和HAVING的区别:WHERE过滤行(未分组时),HAVING过滤组(已分组后),且HAVING可使用聚合函数。WHERE尽早过滤数据,减少后续分组/排序的计算量。
示例:
假设有两张表:编程客栈
student(学生表):id(学号)、name(姓名)、class(班级)score(成绩表):stu_id(关联学生 id)、subject(科目)、score(分数)
查询每个班级中数学平均分≥80 分的学生,显示班级、学生姓名、数学分数,结果按分数降序排列,只看前 2 名。
SELECT s.class, s.name, sc.score FROM student s JOIN score sc ON s.id = sc.stu_id -- 关联条件 WHERE sc.subject = '数学' -- 只看数学成绩 GROUP BY s.class, s.name, sc.score -- 按班级、学生、分数分组 HAVING AVG(sc.score) ≥ 80 -- 筛选平均分≥80的组 ORDER BY sc.score DESC -- 按分数降序 LIMIT 2; -- 只取前2条
实际执行顺序:
① FROM 阶段
- 操作:确定数据源,将
student(别名s)和score(别名sc)作为初始表。 - 结果:生成两张表的笛卡尔积(所有可能的行组合,暂未过滤)。
② ON 阶段
- 操作:使用
ON s.id = sc.stu_id过滤笛卡尔积,只保留学生id匹配的行(关联有效数据)。 - 结果:得到“学生-成绩”的有效关联记录(例如:学生id=1对应其所有科目成绩)。
③ JOIN 阶段
- 操作:执行
JOIN合并,此时结果集仅包含student和score中id匹配的记录(内连接效果)。 - 结果:合并后的临时表包含字段:
s.id、s.name、s.class、sc.stu_id、sc.subject、sc.score。
④ WHERE 阶段
- 操作:用
sc.subject = '数学'过滤行,只保留数学科目的记录。 - 注意:此阶段不能用
AVG(sc.score)(聚合函数),因为尚未分组。 - 结果:临时表中仅剩下“数学”科目的学生成绩记录。
⑤ GROUP BY 阶段
- 操作:按
s.class, s.name, sc.score分组(此处分组字段包含分数,实际可简化为按班级+学生分组,此处为演示)。 - 结果:相同班级、相同学生、相同分数的记录被归为一组(为后续聚合计算做准备)。
⑥ HAVING 阶段
- 操作:用
AVG(sc.score) ≥ 80筛选分组,只保留数学平均分≥80的组。 - 注意:此阶段可使用聚合函数(已分组)。
- 结果:仅保留符合条件的组(例如:班级“高一1班”的学生“张三&rdhttp://www.devze.comquo;数学平均分85分)。
⑦ SELECT 阶段
- 操作:从分组后的结果中选择需要的列:
s.class、s.name、sc.score。 - 结果:临时表字段精简为这三列。
⑧ DISTINCT 阶段
- 操作:这里没有用
DISTINCT,如果有在这阶段对SELECT的结果去重。
⑨ ORDER BY 阶段
- 操作:按
sc.score DESC对结果排序(分数从高到低)。 - 结果:排序后的临时表(例如:分数95→90→85…)。
⑩ LIMIT 阶段
- 操作:用
LIMIT 2只保留前2条记录。 - 最终结果:
| class | name | score |
|---|---|---|
| 高一1班 | 张三 | 95 |
| 高二2班 | 李四 | 90 |
到此这篇关于MySQL 增删改查操作与 SQL 执行顺序详解的文章就介绍到这了,更多相关mysql增删改查内容请搜索编程客栈(www.devze.com)以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程客栈(www.devze.com)!







 加载中,请稍侯......
加载中,请稍侯......
精彩评论