目录前言一、先搞懂:多表关联的底层原理二、优化核心原则三、具体优化方案(从易到难,优先落地低成本方案)(一)基础优化:SQL 写法层面(零成本,优先落地)1. 明确驱动表,小表在前(左连接 / 右连接陷阱)2. 关
目录一、UUID作为主键1、UUID在B+Tree中的存储方式2、UUID作为主键的性能问题二、使用UUID解决排序问题:小结三、mysql删除数据对页的影响1、删除中间数据时的B+Tree变化(可能会导致页合并)2、InnoDB的实际对页合并
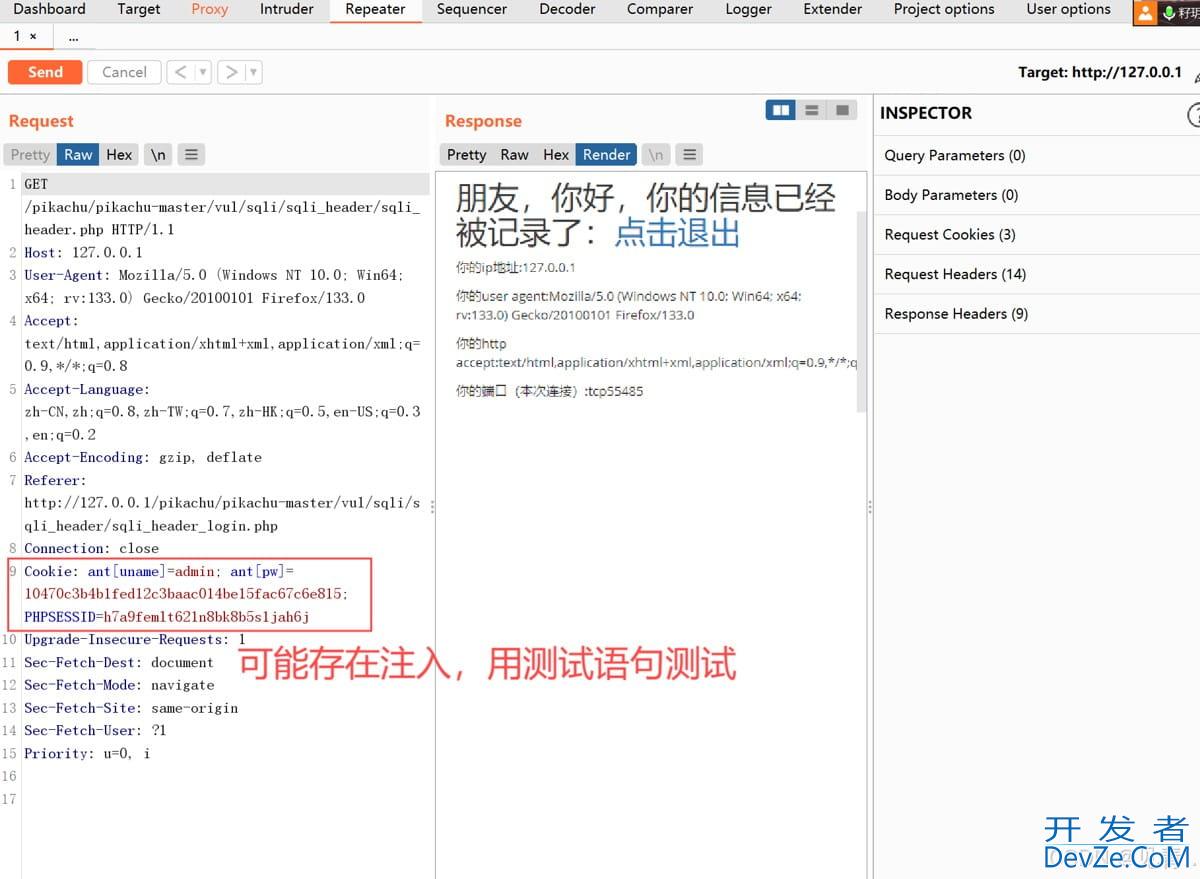
目录一、概念二、原理三、报错注入分类四、三个常用的用来报错的函数1.updateXML()2.extractvalue()五、实战演练1、爆数据库版本信息2、爆数据库当前用户3、爆数据库4、爆表5、爆字段6、爆字段内容总结一、概念
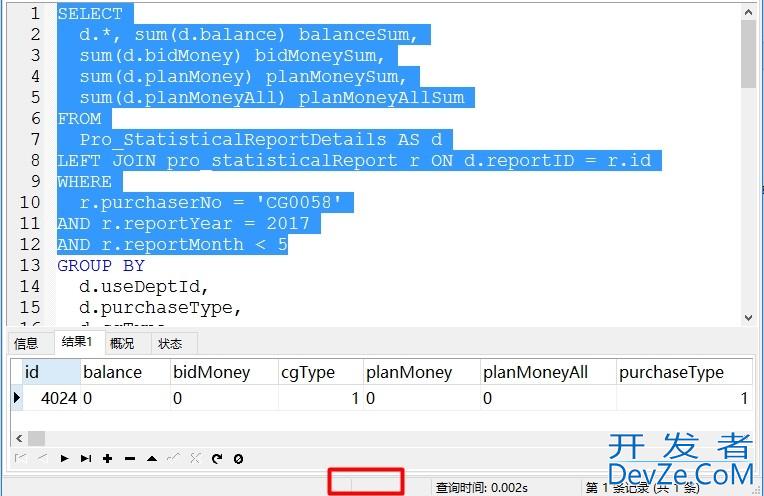
目录Navicat查询到的数据不能修改没有使用group by可以修改使用了group by只读总结Navicapythont查询到的数据不能修改
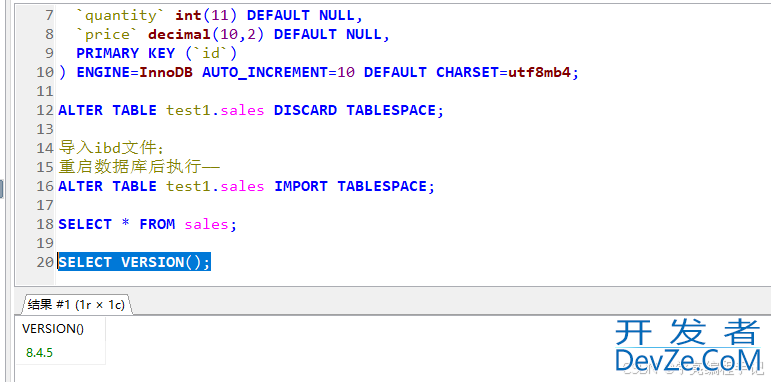
目录主要sql脚本重要前提与警告迁移场景与步骤场景一:从运行中的mysql服务器迁移(最常用)场景二:从物理备份文件恢复(仅有 .frm 和 .ibd 文件)总结与工作流图示基于 *.ibd 和 *.frm 文件进

前言1). 官方说明:Hadoop KMS是一个基于 Hadoop的 KeyProvider API的用密码写的 key 管理server。Client是一个KeyProvider的实现,使用KMS HTTP REST API与KMS交互。 KMS和它的客户端内置安全和它们支持HTTP SPNEGO

hadoop+spark+hive 启动pyspark终端,提示报错 ERROR ObjectStore: Version information found in metastore differs 2.1.0 from expected schema version 1.2.0. Schema verififcation is disabled hive.metastore.s

目录1、所用软件版本2、连接步骤3、注意事项总结1、所用软件版本 www.devze.comNavicat:Navicat Premium 12.1.20oracle:Oracle Database 10g Express Edition Release开发者_数据库教程 10.2.0.1.0Windows:Window

今天在群里聊到cluster全部做主的话,如果一台down机,数据还可以不可以写入。

这篇文章主要介绍了解决Navicat远程连接MySQL出现 10060 unknow error的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
 加载中,请稍侯......
加载中,请稍侯......
精彩评论