目录1. 数据统计基础与环境配置1.1 python数据科学生态系统1.2 环境配置与安装2. 数据获取与加载2.1 从不同数据源加载数据2.2 数据基本信息查看3. 数据清洗与预处理3.1 缺失值处理3.2 数据转换与编码4. 描述性统计分
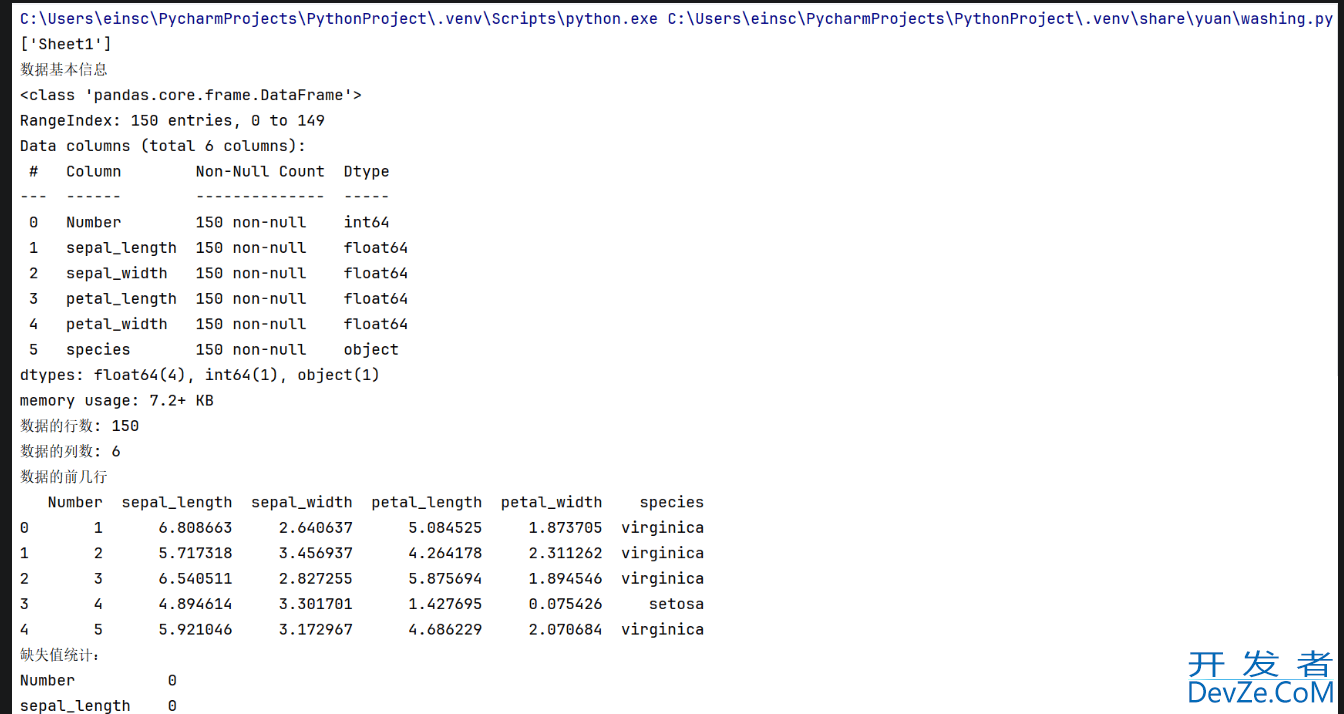
目录前言了解数据清洗数据清洗的步骤1. 环境准备与库导入2. 数据加载3. 数据初探与理解4. 缺失值处理5. 重复值处理6. 异常值处理7. 数据类型转换8. 数据标准化 / 归一化(预处理)实例实践总结前言
基于python抽取目录下所有“jsonl”格式文件。遍历文件内某个字段进行抽取并合并。
目录一、业务场景与痛点分析二、技术方案设计三、代码深度解析四、实战操作指南五、行业应用场景拓展六、性能优化建议七、工具扩展方向一、业务场景与痛点分析
目录一、引言二、数据重复问题的常见场景与影响三、python在数据清洗中的优势四、基于Python的表格字段智能去重技术原理五、代码示例与实战案例六、性能优化与扩展功能七、结论一、引言
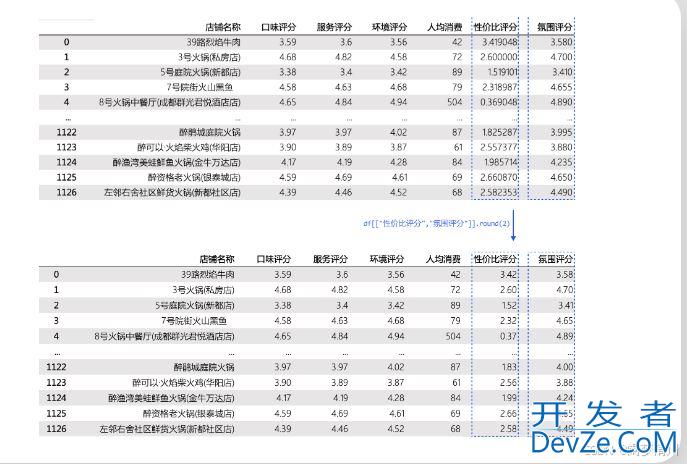
目录1.库的相关简介2.数据处理之添加新列3.处理结果的小数位数的处理4.对于某一列的数据进行排序5.选择我们想要的数据集合6.脏数据的介绍6.1背景介绍6.2时间序列转换7.数据清洗7.1快速浏览数据7.2找到缺失值8.分类对
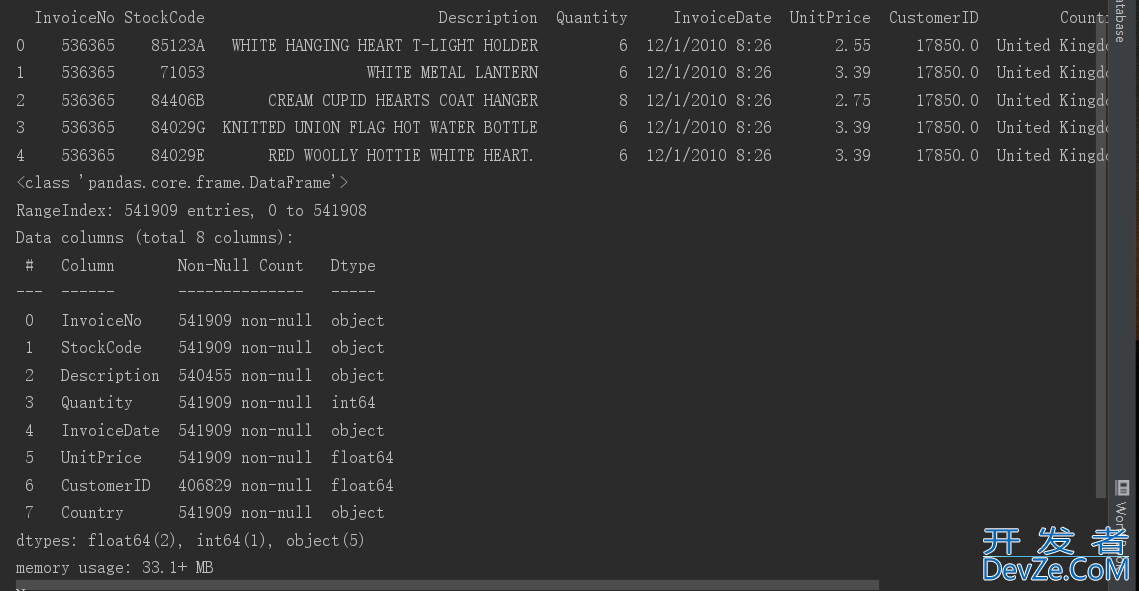
目录空值处理异常值处理重复值处理删除重复值这里数据清洗需要用到的库是pandas库,下载方式还是在终端运行 : pip install pandas.
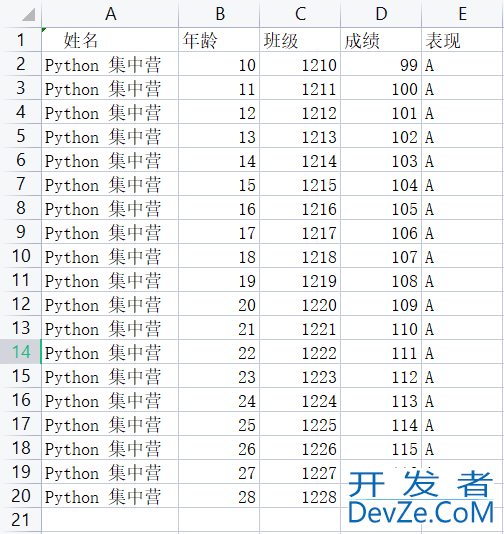
目录1. strip函数清除空格2. duplicated函数清除重复数据3. 数据缺失值补全4. 数据保存关于python数据处理过程中三个主要的数据清洗说明,分别是缺失值/空格/重复值的数据清洗。
 加载中,请稍侯......
加载中,请稍侯......