目录一、功能概述二、核心实现代码1.获取Base64图片数据2 .移除数据前缀3.创建临时文件4.转换图片格式5.调整图片方向6.上传到OSS7… 返回文件URL三、关键技术点解析1. Base64数据处理2. 图片压缩优化3. Exif方
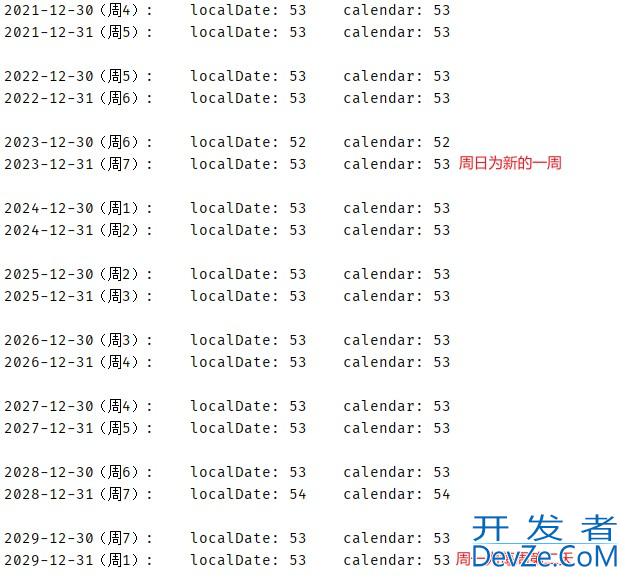
目录Java8及以上版本可以采用LocalDate/LocalDateTimejava8以下版本使用Calendar总结编程中经常遇到日期计算,由于项目中使用到按周统计数据,但是mysql中按所在月的周数周统计比较麻烦,于是采用所在年的周数作为分

目录1、Spring Boot自动装配是什么?2、自动装配原理3、总结1、Spring Boot自动装配是什么?
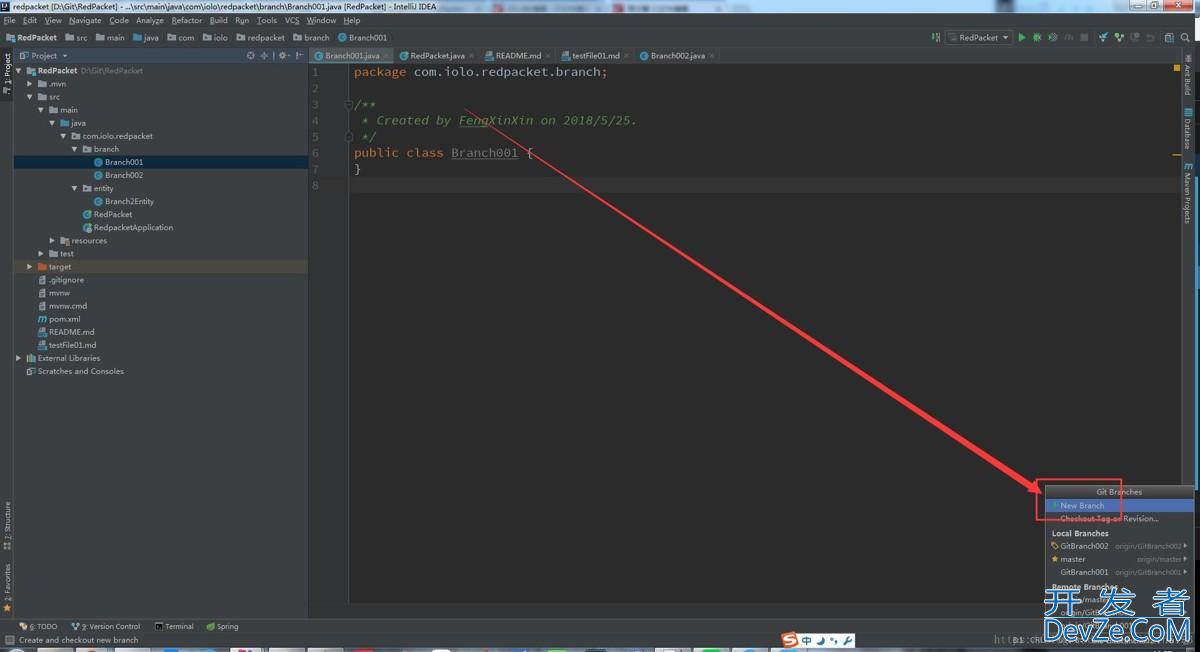
目录简单记录IDEA中Git分支操作1、创建分支2、不同分支merge操作总结简单记录IDEA中Git分支操作
目录问题描述举例说明排查分析解决方法扩展验证总结 问题描述 springboot应用昨天还能正常好好启动,忽然之间就启动不了了,也不报任何错误,只见到控制台输出"Stopping service".这个问题已经连续出

目录基本知识基本思路步骤1、前端配置好tinymce富文本编辑器2、获取富文本编辑器的内容,并发送至后端3、后端在数据库创建表4、后端编写接收富文本内容的接口总结基本知识

目录问题描述解决办法总结问题描述 没有发现测试/空套件 javascript &n编程客栈bsp;

pip安装pyspark报错 python版本:Python 2.7.14 执行命令:pip install pyspark 报错 :return base64.b64encode(b).decode("ascii") MemoryError

目录游戏规则实现代码游戏规则 这是一个单人钻石棋游戏,游戏中有两种颜色的棋子:红色和绿色。每个玩家在游戏进行中轮流选择一个空格,并在该空格上放置自己的棋子。游戏的目的是尽可能地连成一条长的直线,使该直线

Sublime Text 3是一个非常好的代码编辑器。因为它的性感高亮代码配色,也因为它的体积小。但是它默认不支持GBK的编码格式,因此打开GBK代码文件,如果其中有中文的话,就会显示乱码:
 加载中,请稍侯......
加载中,请稍侯......
精彩评论