目录前言窗口函数完整列表排名函数(Ranking Functions)聚合函数(Aggregate Functions)分析函数(Analytic Functions)分布函数(Distribution Functions)每个函数详细介绍1. ROW_NUMBER()2. RANK()3. DENSE_RAN
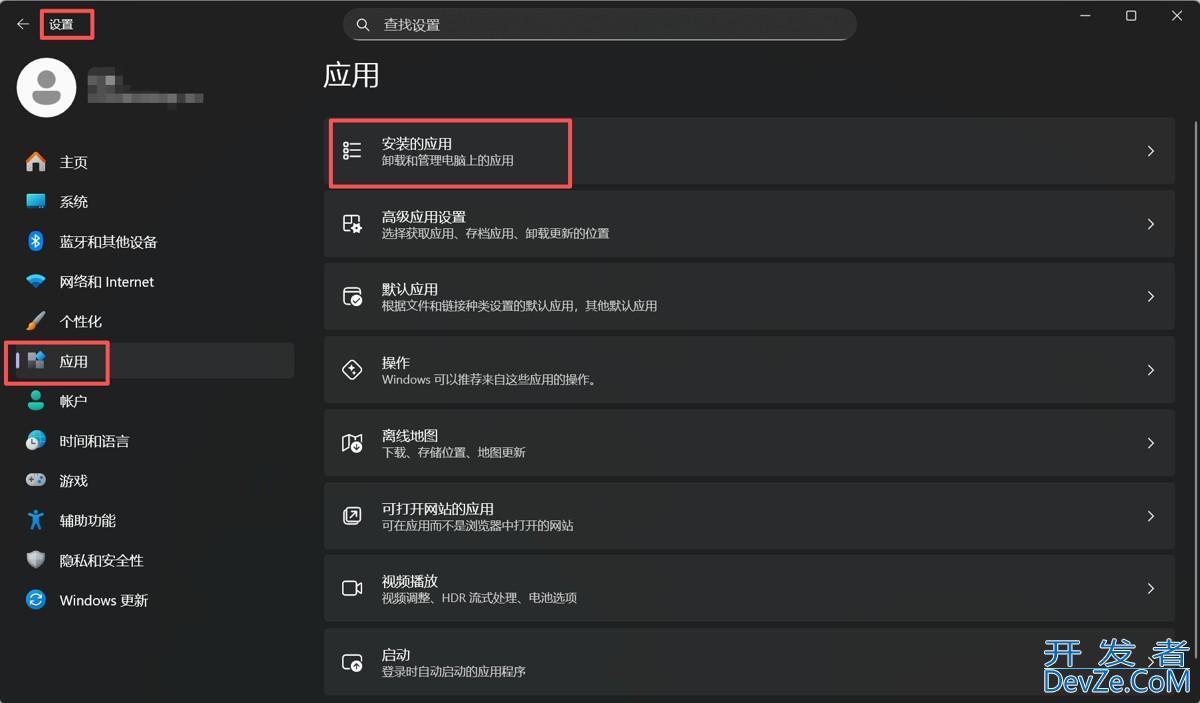
目录常规卸载步骤注册表清理步骤物理文件删除步骤额外注意事项常规卸载步骤
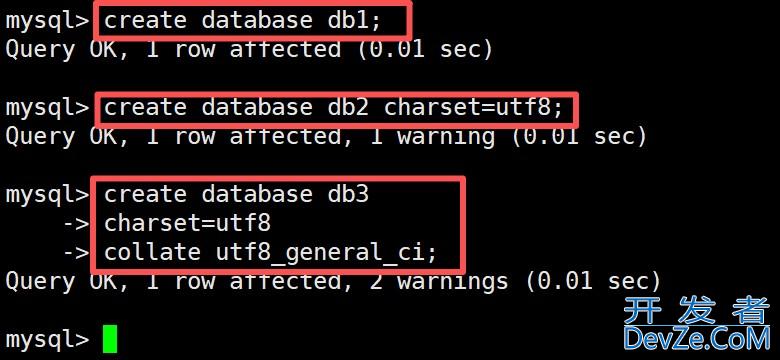
目录一、库的操作1.1创建数据库基础语法创建数据库案例:1.2 查看数据库状态1.php3字符集和校验规则实操验证:1.4 修改、删除与备份数据库(需谨慎,避免风险)1.5查看连接情况二、表的操作2.1 创建表不同存储引擎的文
目录1. 单表查询回顾:夯实基础操作1.1 多条件筛选查询1.2 自定义排序查询1.3 聚合与筛选结合查询2. 多表查询:关联多张表取数2.1 两表关联查询2.2 三表关联查询3. 自连接:同一张表的 “自我关联”4. 子查
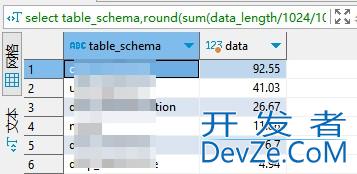
目录适用背景mysql每个库的大小,单位MB具体库下的单表大小,单位MBpgsql每个库的大小,单位MB统计schema下单表大小,单位MB总结适用背景

前言1). 官方说明:Hadoop KMS是一个基于 Hadoop的 KeyProvider API的用密码写的 key 管理server。Client是一个KeyProvider的实现,使用KMS HTTP REST API与KMS交互。 KMS和它的客户端内置安全和它们支持HTTP SPNEGO

hadoop+spark+hive 启动pyspark终端,提示报错 ERROR ObjectStore: Version information found in metastore differs 2.1.0 from expected schema version 1.2.0. Schema verififcation is disabled hive.metastore.s

目录1、所用软件版本2、连接步骤3、注意事项总结1、所用软件版本 www.devze.comNavicat:Navicat Premium 12.1.20oracle:Oracle Database 10g Express Edition Release开发者_数据库教程 10.2.0.1.0Windows:Window

今天在群里聊到cluster全部做主的话,如果一台down机,数据还可以不可以写入。

这篇文章主要介绍了解决Navicat远程连接MySQL出现 10060 unknow error的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
 加载中,请稍侯......
加载中,请稍侯......
精彩评论