分布式缓存redis使用及说明
目录
- 1 Redis单机(单节点)部署缺点
- 2 redis(是单线程的)集群(分布式缓存redis)
- 2.1 解决redis单机部署的缺点
- 2.2 redis的RDB和AOF持久化
- 1 RDB(redis database backup)
- 2 RDB的fork原理
- 2.3 redis主从集群,实现读写分离(解决并发能力问题)
- 搭建主从集群
- 总结
1 redis单机(单节点)部署缺点
(1)数据丢失问题:redis是内存存储,服务重启可能会丢失数据
(2)并发能力问题:redis单节点(单机)部署在并发量不大的话,也是可以满足要求的,并发量最多几万,无法承受更高的并发。
(3)故障恢复问题:如果redis单节点故障中断,那么会影响应用的使用。
(4)存储能力问题:内存存储无法和磁盘存储做比较,不能满足海量数据的要求。
2 redis(是单线程的)集群(分布式缓存redis)
2.1 解决redis单机部署的缺点
(1)解决数据丢失问题:redis的持久化RDB和AOF
(2)解决并发能力问题:搭建redis主从集群,实现读写分离
(3)解决故障恢复问题:搭建redis哨兵,实现健康监测和自动恢复
(4)存储能力问题:搭建redis分片集群
2.2 redis的RDB和AOF持久化
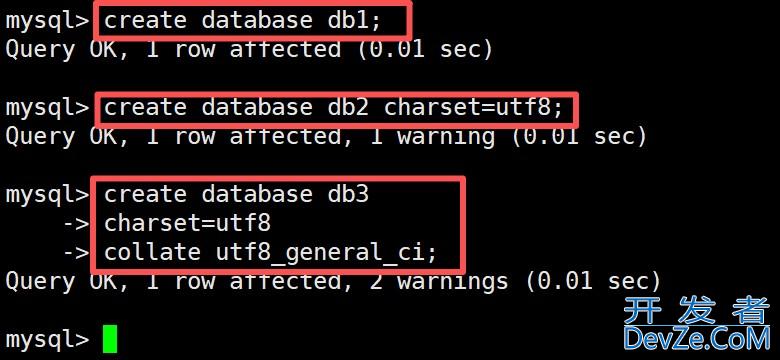
1 RDB(redis database backup)
将内存中的数据都记录到磁盘中,重启后,可读RDB(快照)文件进行数据恢复。快照文件位置:默认保js存在redis运行命令执行的目录下。
redis客户端命令:
redis-cli
>save命令:
执行一次RDB操作,主进程来执行RDB,会阻塞进程。
>bgsave命令:
后台启动,(fork主进程得到子进程)子进程执行RDB,避免主进程受影响。
特殊:如果redis是自己手动停止的,redis停机时会执行一次RDB
2 RDB的fork原理

Bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件。主进程执行fork时,也是阻塞的,只能用来执行fork。
fork就是复制页表(linux的进程和物理内存(内存条)之间映射的虚拟内存),Linux中进程不能直接操作物理内存(内存条) 需要在中间借助一个虚拟内存来映射操作物理内存。
fork操作的范围:
不包括:子进程写新的RDB文件(替换旧的RDB文件)的过程,fork操作只会复制页表(就是进程和物理内存的映射关系表) 生成1个子进程。
思考:
- 如果在fork完一个子进程后,子进程生成R编程客栈DB文件过程中,有请求来修改(写)操作,那么会操作哪一部分?
- 当主进程执行读操作时,访问共享内存。
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作,(只能写这个拷贝的副本数据)。后续的读请求就会访问这个副本数据。
RDB的缺点
RDB执行时间(间隔)长,2次RDB之间写入数据有丢失风险。 如果执行间隔短的话(2-3秒一次),那么太耗性能。
AOF持久化
append only file 追加文件
1 介绍
为了弥补RDB的缺点,redis处理的每一个写命令都会记录在AOF文件中(RDB是每次都重新读全部内存数据),可以看过是命令日志文件。
2 AOF文件体积大的处理方法(将AOF文件中的命令进行重写,相当于将重复命令合成一个(多个set同一个kehttp://www.devze.comy 可合为1个最后的key操作命令))
(1)手动
redis-cli连接redis客户端,执行bgrewirterof命令,用最少的命令达到相同的效果。

(2)自动(在配置文件中添加)
redis也会在触发阈值时自动重写AOF文件,可在redis.conf文件中配置
RDB和AOF持久化的比较

对数据安全性比较高并且数据完整的话:推荐AOF持久化
宕机回复速度要求高的话:推荐RDB持久化
2.3 redis主从集群,实现读写分离(解决并发能力问题)
由于redis大多都是读多写少,所以不做成传统的集群。单节点的redis的并发能力是有上限的,要进一步提高redis的并发能力,需要搭建主从集群,实现读写分离。至少需要3个节点,一主两从,读操作找从节点进行读取,写操作找主节点进行写操作。
另外,主节点master会向两台slave/replica从节点中同步数据。可以解决高并发读(因为有多个slave节点)和高可用性(主从集群的哨兵模式)的问题,但是redis主从集群解决不了高并发写(因为只有一个master)和存储海量数据(整体的存储数据量取决于一个redis节点的master的容量,每个节点数据保持和master节点数据一致)的问题。

搭建主从集群
1 在3台机器上分别安装3个redis
编辑每个redis的redis.conf文件
# redis实例的声明ip redis-announce-ip 所在主机的ip
2 配置主从关系
前android提:3个redis实例还没有关系
(1)临时模式(使用命令配置主从,但重启redis后失效)
redis5.0之前可使www.devze.com用slaveof命令,redis5.0之后新增replicaof命令(和slaveof命令效果一致)
使用redis-cli 客户端连接到redis服务,执行slaveof命令
slaveof 主节点的ip 主节点的端口号
效果:在哪台redis客户端命令/配置文件中 添加上slaveof,那么这台redis就会成为指定的主节点的从节点。
(2)永久模式–修改配置文件
在redis.conf文件中添加一行配置:
slaveof 主节点的ip 主节点的端口号
在某一台redis中查看节点信息:
info replication
主从数据同步原理
建立连接时的第一次同步 是全量同步

(1)2个重要概念
- Replication id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave会继承master节点的replid。
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。
master节点判断某个从节点是否第一次同步:
每个redis节点都有自己replication id,每个redis从节点都有自己的replication id和相对于主节点的偏移量offset。
连接redis
bin/redis-cli # 在bin目录下 连接 redis-cli
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程客栈(www.devze.com)。





 加载中,请稍侯......
加载中,请稍侯......
精彩评论