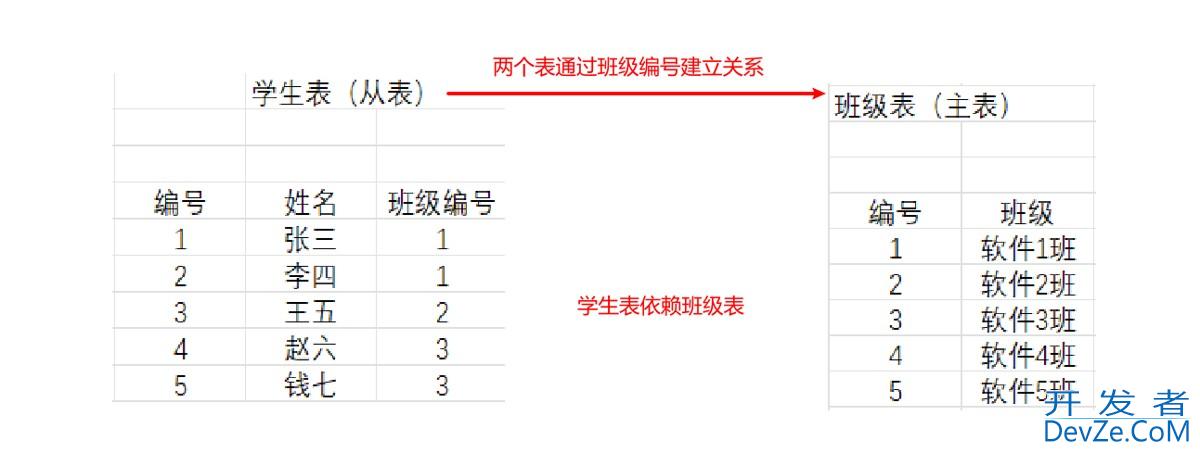
MySQL如何实现跨库join查询
目录
- mysql实现跨库join查询
- 同服务器的不同库
- 不同服务器的不同库
- 数据库跨库join方案
- 总结
MySQL实现跨库joinjs查询
同服务器的不同库
只需要在表名前加上db_name
select * from upythonserdb.user u join orderdb.`order` o on u.id = o.user_id;
不同服务器的不同库
1.查看配置 FEDERATED
SHOW engines;

如果是NO,需要改为YES.默认是NO
在my.ini文件中增加一行,重启MySQL 服务即可
federated
2.在本地库创建相同的表建立连接
开发者_KafkaCREATE TABLE `order` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_id` bigint NOT NULL, `product_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE =FEDERATED CONNECTION='mysql://root:123456@192.168.10.100:3306/orderdb/order';
注意:本地创建的表名必须在远程服务器存在,创建的字段也必须是远程表中的字段,可以比远程表的字段少,但是不能多,本地存储引擎选择:ENGINE =FEDERATwww.devze.comED,
CONNECTION选项中的连接字符串的一般形式如下:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
配置密码作为纯文本的话会存在安全问题,运行show create table,show table status是可以见的
note:
- 本地表结构必须与远程完全一样
- 远程数据库只能连接MySql;
- 不支持事务;
- 不支持表结构的修改
- 本地表更新,远程表也同步更新,反之亦然
- 删除本地表,远程表不会删除
数据库跨库join方案
最好不要出现跨库join,应该在设计的时候就避免。
将需要join的表放在同一数据库,即便是分库分表看能不能按相同维度分到一起。
或者看能不能设冗余字段,避免关联查询。
那如果无法避免跨库join,也应该走微服务API查询,或者使用中间件实现。
比如:
1.调用两个服务API分别查询,再组装数据;
2.利用Canal,将数据同步到业务系统数据库;
3.将两个服务的数据实时同步到一个只读库,然后在只读库查询;
一定要跨库join,MySQL也是可以支持的:
1.开启FEDERATED引擎,修改my.ini(或my.cnf)文件新添加一行,内容为federated,然后重启MySQL。
2.在数据库中建立远程表,通过参数CONNECTIOwww.devze.comN='mysql://username:pwd@ip:端口/库名/表名
3.直接在SQL语句使用join即可。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。







 加载中,请稍侯......
加载中,请稍侯......
精彩评论